Artificial neural networks are Artificial Intelligence models that try to mimic the brain in the way it stores knowledge and processing information. Artificial Neural Networks which are commonly known as Neural Networks have been motivated from its inception by the recognition that the human brain computes in an entirely different way from the conventional digital computers. The first wave of interest in neural networks emerged after the introduction of simplified neurons by McCulloch and Pith in 1943. These neurons were presented as models of biological neurons that could perform computational tasks.
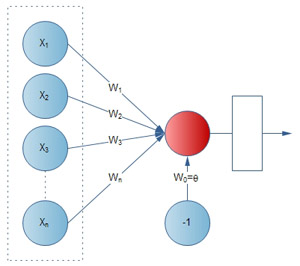
A Neural Network consists of a pool of simple processing units which communicate by sending signals to each other over a large number of weighted connections. The idea is to create a mathematical function to mimic a neural communication. This can be achieved by the following points:
- Represent a neuron as a boolean function.
- Each neuron can have an output capacity of either 1 or 0.
- Each neuron also has a set of inputs (either 0 or 1), with as associated weight.
- The neuron can compute a weighted sum over all the input and compare it to some threshold t.
- If the sum is greater than t, then output 1 else output 0.
Perceptron:
A perceptron is a simulated neuron that takes the agent's percepts (eg. feature vectors) as input and maps them to the appropriate output value.
This can be represented in an equation form as follows:
w1 * x1 + w2 * x2 + ........ + wn * xn >= t
Perceptron Learning:
Now the most important question which should be haunting you by now. How does the perceptron learn ? Well, a perceptron learns by adjusting its weights in order to minimize the error on the training set. To start off, consider updating the value for a single weight on a single example x with the perceptron learning rule:
wi = wi + error
error = a * ( true value - output) * xi
where a is the learning rate having value from 0 to 1.
Now that we can update a single value on one example, we want to update all weights so that we minimize error on the whole training set. Now this is really an optimization search in weight space, which is the hypothesis space for perceptrons.
Now the question is how do we begin ? Its simple, just initialize all the weights to small random values. Now we train our neural network by supplying input values to it and also giving it the expected output values to adjust its weights. The perceptron training rule allows us to move to the point in weight space that minimizes the error.
This a very brief introduction to neural networks for those who want to get an insight into Neural Networks. Buts there is a lot more to explore and a lot more complexity involved.
No comments:
Post a Comment